1 min to read
音乐爬虫分析
教你用python轻松下载音乐!
原帖
教程
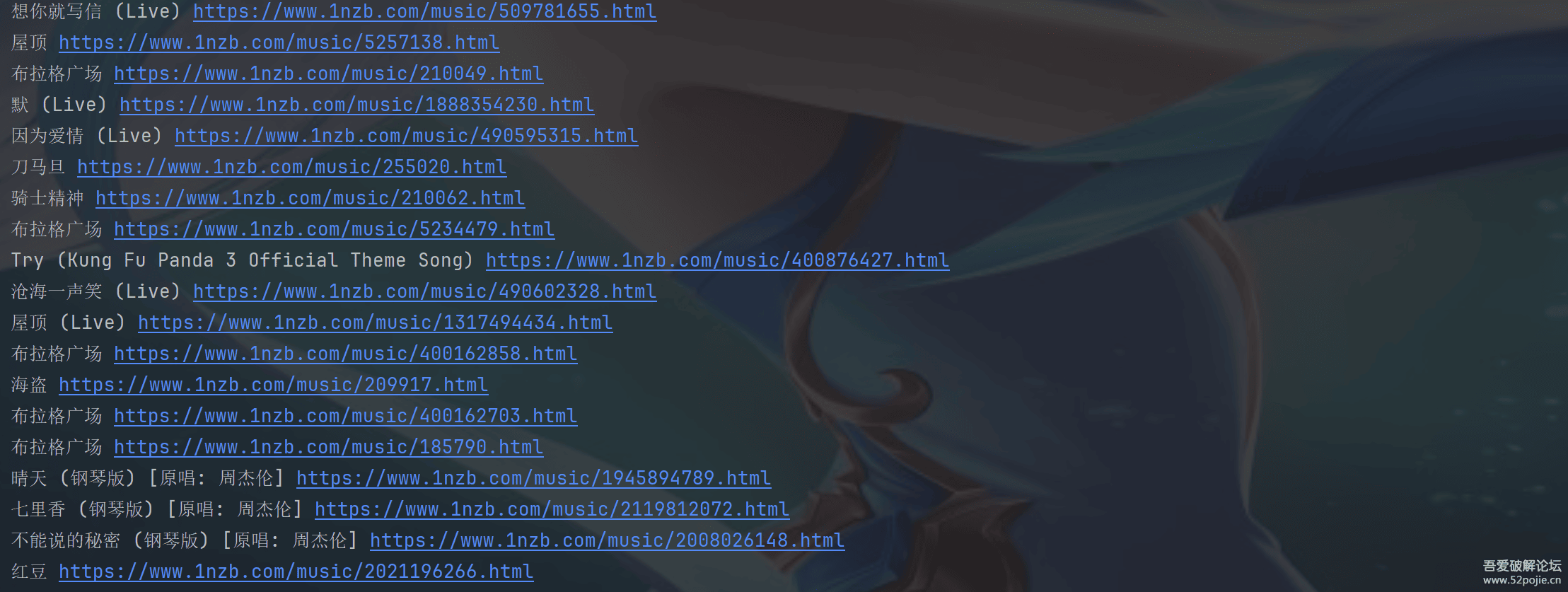
随便找个下歌的网站,我是随便搜的 网址:爱听音乐网_Mp3歌曲下载_无损音乐下载_免费音乐网_LRC歌词下载站 有了网址我们就可以对搜索的接口分析,看他的参数怎么传入,实现搜索

简单搜索一下

可以看到的是,接口是https://www.1nzb.com/search?ac,通过ac传入搜索的关键词:周杰伦
这样就可以写出第一次请求的url地址,同时通过关键字进行自己需要的搜索
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
ua = UserAgent().random
url = 'https://www.1nzb.com/search?ac=周杰伦'
headers = {
'User-Agent':ua
}
response = requests.get(url, headers=headers)
这里为了方便测试先将请求url写死 然后根据页面信息进行解析

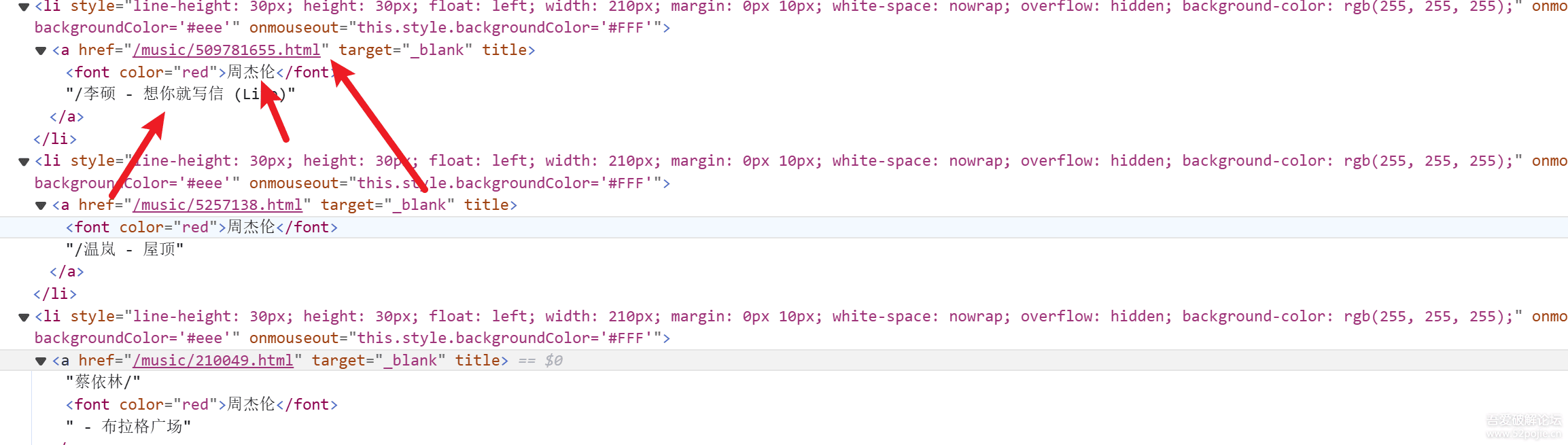
可以清晰的看到需要的数据所在的位置li标签里面a标签,这个里面有点小坑就是名字不好处理
接下来就是通过汤勺(soup)进行解析
soup = BeautifulSoup(response.text, 'lxml')
lists=soup.select('ul.mul li')
这里定位到所有的li标签,接下来就是用for循环遍历获取li标签的中的内容 首先获取a标签的属性href,得到一个url地址,但是这个地址需要拼接才能访问,拼接https://www.1nzb.com,需要注意的是/的数量 接下来获取歌曲的名字,我们可以注意到每个名字前都要一个‘-’,我们可以利用正则也可以利用split函数进行分割 代码如下:
for li in lists: produce_url='https://www.1nzb.com'+li.find('a').get('href')
song_name=li.find('a').text.split('-')[1]
这样我们可以放一个空字典,让歌曲名字和下载网址作为键值对相互对应,实现输入歌曲名字就可以进入下载的地址,输入哪一首歌名就下载哪一首
dic[song_name]=produce_url
注意dic是需要提前定义的
接下来就是解析produce_url作为下载的路径

网站很友好(大家下手也友好一点,加点延时),可以直接用re或者bs解析,我们也看看网页元素是什么情况

这个获取还是很简单的,爬虫的基本功
down_url=soup.find('input',class_='layui-input').attrs['value']
这样就获取到了mp3下载的url,接下来就直接请求下载
music=requests.get(down_url,headers=headers).contentwith open('music.mp3','wb') as f:
f.write(music)
一个简单的爬虫步骤分析,大佬们勿喷 提供给想了解的小白

评论